
Backend development at scale is no longer about frameworks, endpoints, or writing code that works. At an advanced level, backend development is not about frameworks, syntax, or clever abstractions. It’s about designing resilient, scalable, maintainable systems that survive reality: traffic spikes, network failures, partial outages, human mistakes, and evolving teams.
Having led and designed systems that have scaled from hundreds to millions of users, I want to share the patterns, trade-offs, and concrete examples that make the differences.
This guide documents the principles to build scalable, resilient, production-grade systems.
1. Systems Design Over Endpoints — Real Signup Flow Example
Junior devs think API endpoints. Leads think flows and failure modes.
Scenario: Signup Flow with External Dependencies
Requirements:
- Register user credentials
- Send welcome email
- Log analytics
- Create billing profile
- Enable feature flags
Naive Synchronous Design
POST /signup
→ create user record
→ send welcome email (blocking)
→ create billing profile (blocking)
→ log analytics
→ enable feature flags
→ respond 200 OK
Why this is bad:
- If the email service is down, signup fails.
- Latency depends on the slowest external call.
- System is tightly coupled and hard to scale.
- No clear failure isolation.
Lead-Level Design: Asynchronous, Event-Driven, Resilient
Architecture diagram description:
- Client calls
POST /signup→ User Service creates user record with statusPENDING. - User Service emits a
UserCreatedevent on an Event Bus (Kafka, RabbitMQ, or similar). - Email Service asynchronously consumes
UserCreatedand sends a welcome email. - Billing Service consumes the event and creates a billing profile.
- Analytics Service consumes the event to log metrics.
- Feature Flags Service listens and enables features.
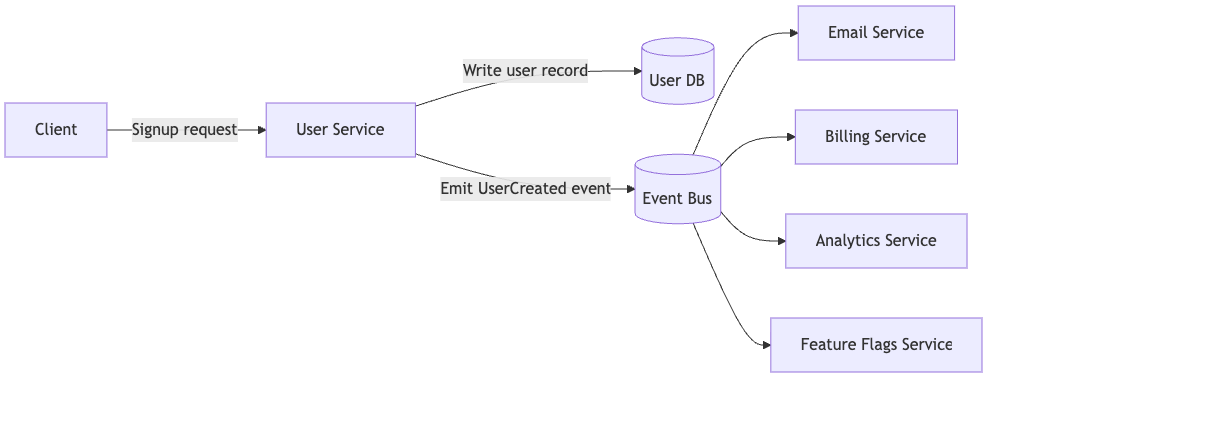
Explanation:
POST /signupwrites user record synchronously.- Emits a
UserCreatedevent on Event Bus (Kafka/RabbitMQ). - Other services consume events asynchronously and retry on failure.
Code snippet — event emission in Node.js:
// userService.js
async function signupUser(userData) {
const user = await UserModel.create(userData);
await eventBus.publish('UserCreated', { userId: user.id, email: user.email });
return user;
}
Tooling suggestion:
- Use Kafka or RabbitMQ for reliable event streaming.
- Implement dead-letter queues (DLQs) for failed events.
2. Data Modeling for Reality — Orders System Example
Naive schema (normalized):
Tables:
orders(id, user_id, total, status)order_items(id, order_id, product_id, quantity)products(id, name, price)
Problem query:
Get total revenue per day → expensive joins and aggregations.
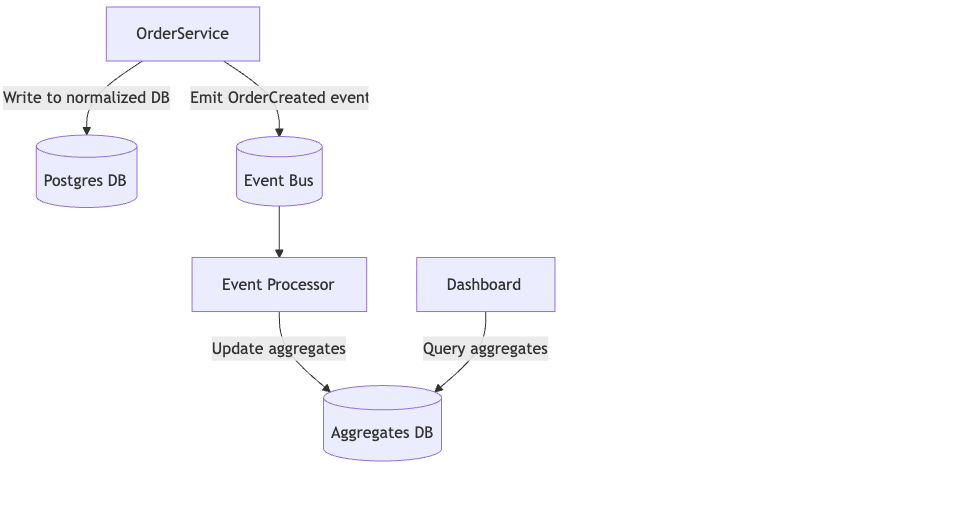
Explanation:
- Write model normalized for ACID.
- Event processor updates denormalized aggregates asynchronously.
- Dashboard queries aggregates, avoiding expensive joins.
Code snippet — event processor updating aggregates:
eventBus.subscribe('OrderCreated', async (event) => {
const { date, total } = event.payload;
await AggregatesDB.query(`
INSERT INTO daily_order_stats(date, total_revenue, order_count)
VALUES ($1, $2, 1)
ON CONFLICT (date)
DO UPDATE SET
total_revenue = daily_order_stats.total_revenue + $2,
order_count = daily_order_stats.order_count + 1
`, [date, total]);
});3. Transaction Boundaries & Consistency — Payment Flow
POST /checkout
→ create order
→ charge card (external API)
→ mark order paidProblem:
- Failures cause duplicate charges or lost updates.
- If payment gateway succeeds but response is lost, system inconsistencies arise.
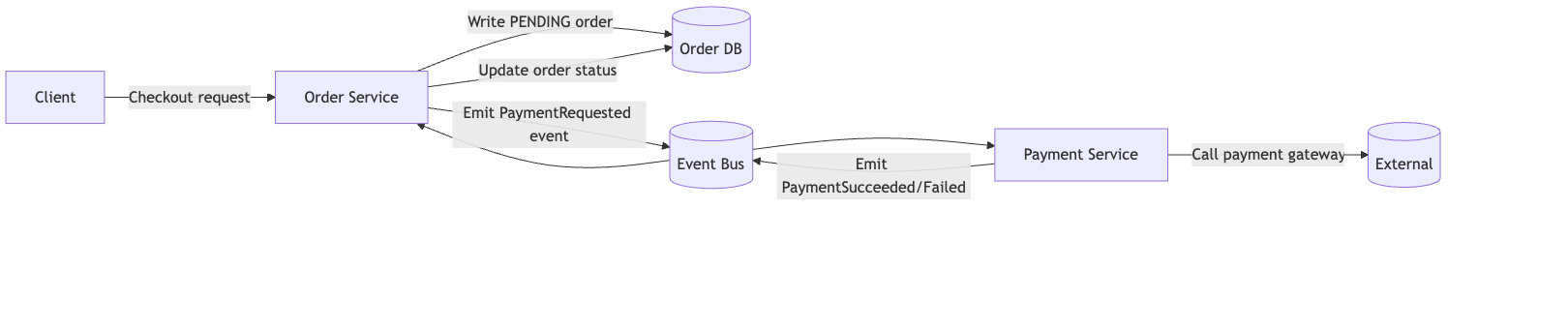
Robust Event-Driven Flow
Steps:
- Client calls
/checkout→ Order Service creates order withPENDINGstatus.
2. Order Service emits PaymentRequested event.
3. Payment Service listens:
- Charges card.
- Emits
PaymentSucceededorPaymentFailed.
4. Order Service updates order status accordingly.
Idempotency:
- Payment Service tracks transaction IDs.
- Duplicate events are ignored.
- Webhook duplicates handled safely.
4. API Design for Longevity and Compatibility
APIs are contracts that live far longer than their creators.
Common anti-patterns:
Breaking clients with minor changes
Ignoring backward compatibility
Versioning by URL path (/v1, /v2), leading to maintenance hell
Better Practices
- Use media type versioning in headers (
Accept: application/vnd.myapi.v2+json) - Add new fields; don’t remove or rename existing ones.
- Mark deprecated fields clearly.
- Use feature flags to toggle behaviors.
This lets you evolve APIs without breaking existing clients.
5. Asynchronous Architecture & Event Thinking
Synchronous monoliths break under load and complexity.
Events are facts about what happened.
Example: Deleting a user:
- Emit
UserDeleted { user_id, timestamp } - Consumers revoke access, delete data, cancel subscriptions asynchronously.
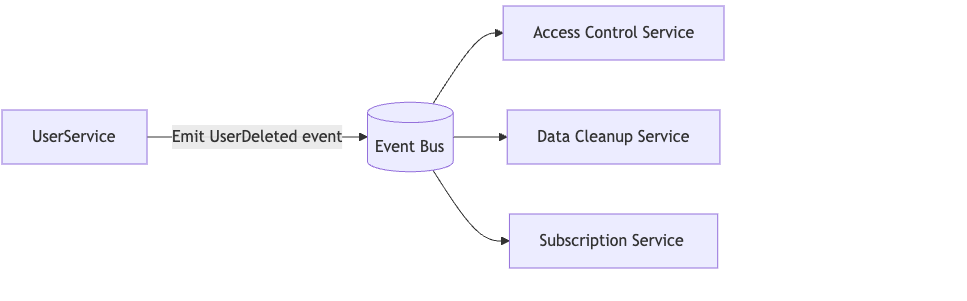
This ensures:
- The deletion API is fast and reliable.
- Downstream systems can process independently.Retry and ordering issues can be handled per consumer.
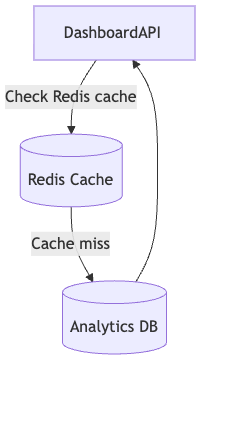
6. Caching as Architecture, Not Optimization
Caching decisions require clear ownership.
Example: Dashboard Cache
- Use Redis or similar to cache dashboard query results for 5 minutes.
- Cache invalidation triggered by write services emitting invalidation messages.
- Avoid infinite TTLs or guesswork.
7. Reliability Engineering — Circuit Breaker Pattern
Problem:
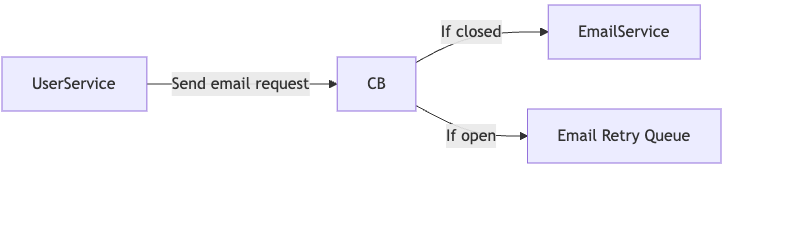
Email service is flaky and causes request timeouts.
Solution:
- Add a circuit breaker to email calls.
- After 5 failures in 10 seconds, circuit opens.
- Requests fail fast, emails queued for later.
- Circuit resets when email service recovers.
This prevents cascading failures and improves user experience.
8. Observability — Distributed Tracing
- Use OpenTelemetry to propagate trace IDs.
- Each service logs structured spans with start/end times.
- Visualization tools (Jaeger, Zipkin) show request flow and latency bottlenecks.
9. Performance & Tail Latency
- Track latency percentiles (P50, P95, P99).
- Identify tail latency sources: slow DB queries, network timeouts.
- Use timeouts, circuit breakers, caching to reduce tail effects.
10. Security as Architecture — Zero Trust Model
- Mutual TLS between services.
- JWT-based auth and authorization for every internal call.
- Audit logs for sensitive operations.
11. Cost-Aware Design — AWS Lambda Example
- Combine small functions to reduce invocation count.
- Use provisioned concurrency for critical flows.
- Analyze cost per request and optimize.
12. Maintainability Over Cleverness
- Favor explicit, readable code.
- Avoid abstractions that obscure flow.
- Write code new engineers can understand in days, not weeks.
13. Senior, Lead, and Staff Engineer Differences
- Senior: solves problems reliably.
- Lead: designs systems and teams that prevent problems.
- Staff: aligns architecture and multiplies impact organization-wide.
Final Words
Building production-grade backends is a craft of judgment under uncertainty.
Mastering these patterns and tools positions you to design systems that:
- Fail gracefully
- Scale predictably
- Are maintainable and observable

{kind=link}